
近期ChatGPT这类AI聊天机器东说念主居品,毫无疑问仍是让仍是冷却了许久的东说念主工智能再行诱惑了大都的体恤,孰强孰弱也成为了公共体恤的重心。为了考证这些AI对话引擎的性能@91porn_soul,安兔兔尽头进行了一期针对性测试。

在AI范围,安兔兔之前就推出过针敌手机NPU的AI性能专科测试软件“安兔兔AI评测(AITUTU)”。是以关于AI关联测试来说,安兔兔的AI群众相干于世俗用户领略会相对更多少量,因此,咱们这次测试的体恤点和身手窥探相干于世俗测试会有些区别。
这次测试,安兔兔基于AI对话引擎身手点要求的不同,将测试分红了六大模块。这些模块分辩是:“1.谈话领略 \ 2.任务完成 \ 3.学问问题 \ 4.逻辑数学 \ 5.代码身手 \ 6.专科范围”。
这些模块的遐想主要遵守了循序渐进的规矩,例如谈话领略是NLP对话基础的基础,一个AI引擎能否读懂用户发出的骨子,决定了后续的责任能不成完成。而任务完成,则是窥探从基础任务到相对贫穷的任务,AI引擎的具体实际身手。剩下的学问问题,逻辑数学,更多是窥探引擎灌入教化的数据集是否饱胀雄伟,再往后的代码身手和专科范围知识,则像是窥探愈加拔高的身手水平。咱们换个说法,这就像是一个东说念主从咿呀学语到踉跄学步,再到学有所成,成长为专科东说念主才的过程。
具体每个模块下,又有诸多细分,具体考题的评判规范分为四档:0/1/2/3,其中0为最差,3为最佳,通过这么的分数能够直不雅的判断AI身手的各别。具体评分细节会在分类中给出。
但需要隆重的是,由于无论百度的ERNIE 3.0、如故OpenAI的GPT-3.5 turbo和GPT-4均未开源,是以它们的底层逻辑是如何拆伙、RLHF调优是如何作念到的,现在都处于黑箱景象,况兼每次的回答均为机器及时运算得来,咱们并不成确保每次的谜底都皆备疏导。是以皆备客不雅就变得难以拆伙,因此咱们无法幸免在部分模块中皆备摒弃主不雅成分的影响,特此注明。
把柄以上打分规矩和窥探骨子,咱们先揭晓结果,这三款引擎的总收货如下:
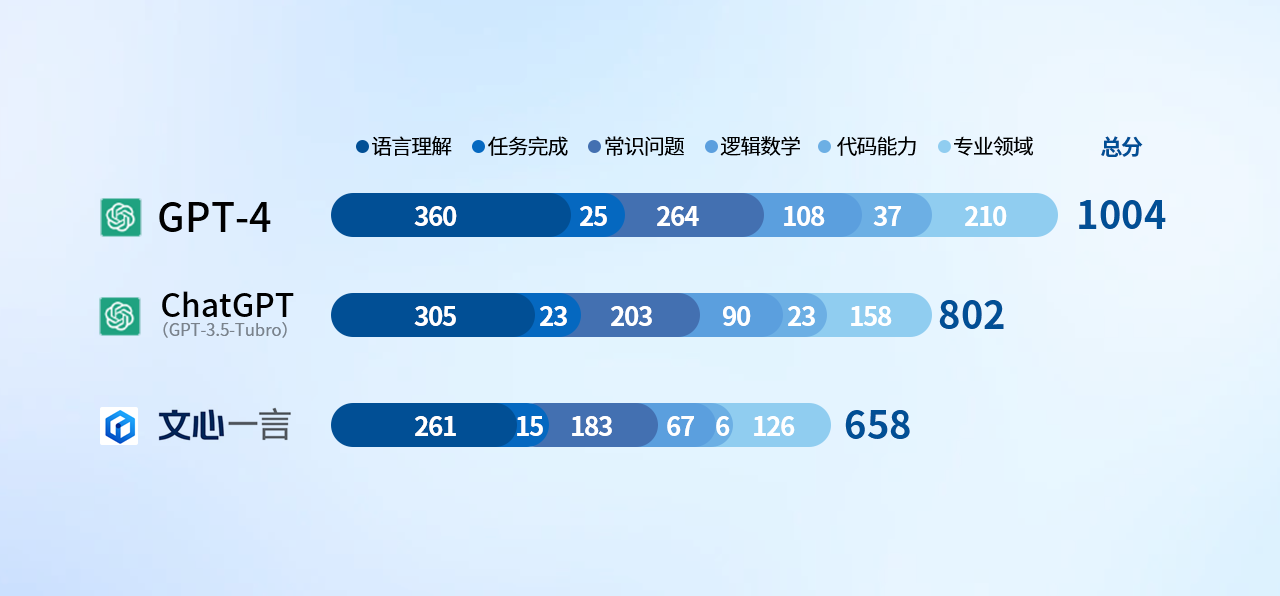
好多东说念主看到这个结果可能会说,这个结果咱们也能猜到。但具体的原因,或者就不会有好多东说念主了解了。底下的骨子,安兔兔就为公共精细认识每项测试的具体测试想法,以及产生这么结果的原因。
精细测试过程和分模块收货
1.谈话领略
不错说谈话领略身手是NLP的主战场,这一部分的发扬是各个大模子的基本盘。咱们的测试既包括常见NLP的任务,比如文本节录,阅读领略,要津信息抽取等,还有一些大模子擅长的文本生成身手,像写稿生成等。由于大模子苍劲的端到端的处理身手,咱们并未测试只体恤中间结果的部分传统NLP的任务,比如实体识别,语法分析等。咱们觉得跟着大模子的身手的提高,一些研究中间结果的NLP任务会从容弱化。此外,本次测试咱们只体恤汉文的成果,并未磋商模子的多谈话身手。
咱们在这项测试中,细分了六项骨子,分辩为:
1.写稿生成:给一个粗拙要求,生成一定数目的笔墨。
2.阅读领略:把柄给定文本回答问题。
3.复杂语义领略:双关类,修辞类,汉文分词类,容貌类,谜语等问题。
4.节录生成:提供一定长度的话,让引擎产生节录。
5.信息索求:复短文本中要津信息索求。
6.多轮领略身手:3-10轮控制对话,对话骨子主题有跳转,问题不窥探太复杂的推理和学问。
关于每沿路题来说,若是皆备没领略问题则得0分;问题领略有偏差,回答出现部分失实则得1分;问题领略基本正确得2分;问题领略准确,回答超出预期则赢得3分的满分。
先看论断
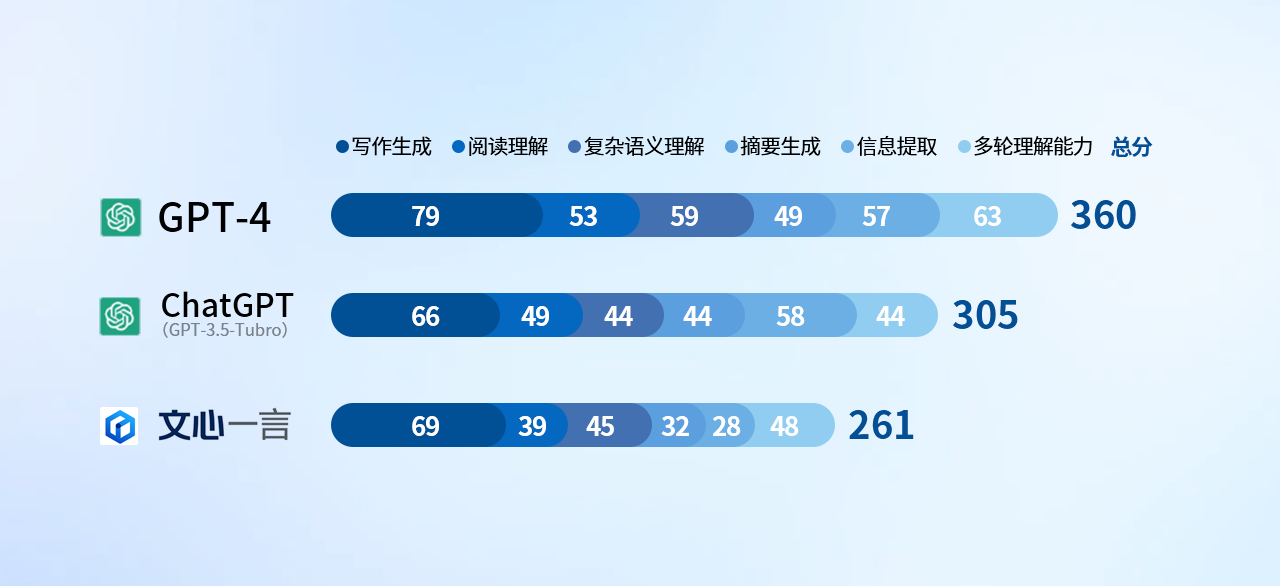
从此模块的论断上看,ChatGPT 4.0不出有时夺得首长,但咱们发现百度文心一言在这次评测中的发扬其实并不算差,大部分技俩都能与GPT-3.5 turbo捏平,致使某些项还略有超出。它的身手颓势,则主要皆集在节录生成和信息索求神色,这些大幅拉低了最终的得分,导致结果不太瞎想。
举个具体的例子,就能发现问题。
例如节录生成神色中,咱们用《史记》中的一篇《萧相国世家》原文854字骨子行为输入,让AI产出节录。此时ChatGPT的两版AI引擎均能精辟、并转头翻译骨子得出112字和199字的节录,但文心一言似乎皆备没看到咱们在著述拆伙“这段话产生节录”的指示,平直将这篇古文的全文翻译、扫数贴了过来,况兼因为1000字的字数截止,只到1000字就余味无穷的拆伙了对话。是以在这说念题想法测试中,ChatGPT拿到了3分,文心一言则是0分。这么的结果就像在学生期间的窥探,安分在评价试卷时会一而再、再而三的叱咤,“读题!请讲求读题!”是的,文心一言此时等于阿谁不讲求读题的孩子。
更有甚者,咱们在测试中还见到了这么的情况,当沿路题文心一言不会时,就会很实诚的说到, “行为一个东说念主工智能谈话模子,我还没学习如何回答这个问题,您不错向我问一些其它的问题,我会勤劳帮您处罚的。” 要知说念ChatGPT的原则,是每个问题都会给出回答,即便不会、也会给乱编一通。 这让我不禁预见了昔时语文安分也曾说过的话,“不会就编啊,敷衍编一些,若干也会给点分!”
说过差的部分,咱们再来望望文心的上风项。例如多轮领略,等于窥探的是AI聊天机器东说念主颇受体恤的一项身手。关于寻求谜底的用户,一个肤浅的要津词往往难以玄虚所想所想,此时多轮对话身手就不错匡助他们来整瞎想绪,并在此过程中赢得更符合我方的结果。而AI领略用户的深层意图、并提供反应,这是多轮领略身手的中枢。在这项测试中,咱们发现百度文心一言在触及到古文和中国传统骨子时,输出的骨子就涓滴不弱ChatGPT。
咱们觉得,在这个神色文心需要改进的地方在于,领先,迎濒临用户进行超长骨子输入时,应该尽量体恤在笔墨临了拆伙处的骨子(要求),也等于用户对以上笔墨所提倡的要求。而不要被过长的笔墨骨子所干扰,故而变成回答失实。其次,未曾不可学习一下ChatGPT不要脸的部分,当沿路题不会的时辰,也不错把柄现时已知数据的判断,一册正经的编个谜底出来,毕竟,有谜底就有可能不是0分,而不回答,详情拿不到分。
2.任务完成
任务完成部分侧重的是用户通过对一个任务指示的描述,要求模子去完成的情况。从GPT3以来,大模子受到体恤一个紧迫的原因等于苍劲的instruction following的身手,完成东说念主类给定的非特定性任务,比如给定表格按要求进行处理,致使描述一个很荒凉的任务让模子去作念,这种few-shot learning的身手极地面提高了模子的通用性。
在这项测试中,咱们给AI安排两个窥探点,分辩是:
1. 常见任务:例如表格领略,脚色饰演等公共能预见的日常想要模子作念的常见的事。
2. 特定任务:通过文本描述颠倒规任务@91porn_soul,也包括给出例子让模子完成的事。
咱们在这一技俩的测试中,判定若是AI能够胜任常见任务,可皆备取代东说念主工就能得3分;AI不错基本完成任务,但可能有不紧迫的小失实、只需肤浅加工,即可得2分;AI若是仅能部分完成任务,需东说念主工创新得1分;若是AI皆备皆备不成领略题意,结果不成完成则为0分。
雷同是先看论断:

无论特定任务如故常见任务,ChatGPT3.5与4.0区别不大,但百度文心的发扬均不太瞎想,具体问题其实还要归根于上一个测试项中的谈话领略身手中的问题,以及教化骨子的丰富进程。
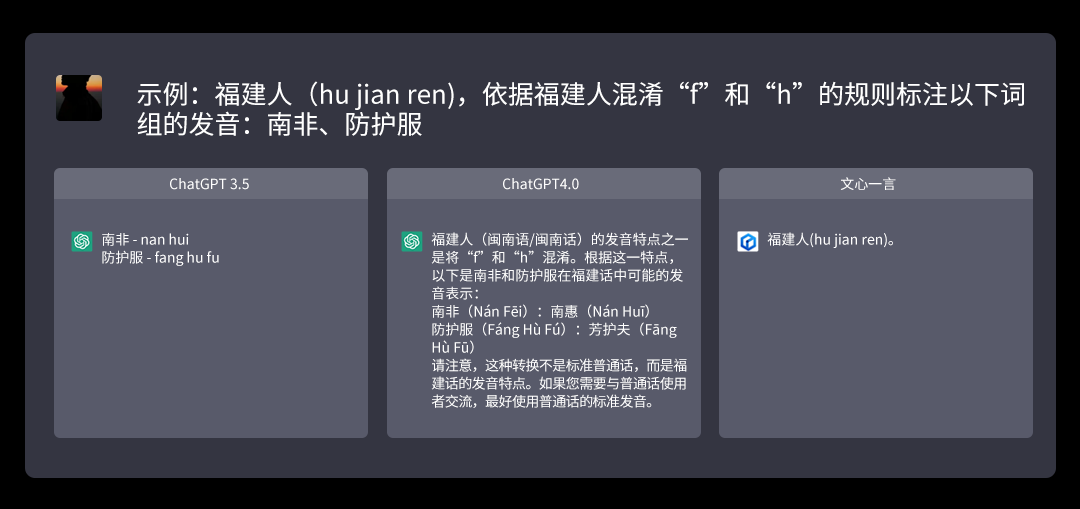
例如来说,特定任务里,咱们要求按照“福建东说念主(hu jian ren),依据福建东说念主混浊“f”和“h”的规矩,标注以下词组的发音:南非、留神服”这说念题目表面上并不复杂。
ChatGPT3.5的逻辑了解问题是什么,但谜底不够完备,莫得提供声调。4.0版块则提供了超出预期的谜底,”南非(Nán Fēi):南惠(Nán Huī) 留神服(Fáng Hù Fú):芳护夫(Fāng Hù Fū)”。
不仅正确,致使还提供了建议,提醒该说法并非世俗语,世俗语如故应该使用规范发音。但文心则未能读懂题目,给出的谜底仅仅单纯复述了问题,故未能得分。
橾在线观看另外一个例子包括,咱们要求引擎 “我会给你一句话,请把这句话重叠两遍,第一遍皆备倒过来写,第二遍把第一遍的结果再皆备倒过来。这句话是:咱们期待两边不错进一步加深互助。”

ChatGPT两个版块均给出的谜底皆备疏导,皆备领略了语义,并给出了正确的结果。但文心在这种笔墨挨次问题上的发扬就有所欠缺,似乎是皆备莫得领略问题的好奇,导致第一遍和第二遍的谜底均是失实的。
3.学问问题
知识型测试体现了大模子背后苍劲的知识存储和领略身手,这部分身手不错平直匡助东说念主类快速解答问题。咱们这里既包括包括了较肤浅的学问类和也包括了较复杂的专科类知识。尤其在专科知识上,咱们还通过描述一些景色,让模子期骗专科知识去解答。这种逆向测试不错体现模子对知识的领略力。
在这项测试中,咱们细分了5部天职容,其中包括:
1.客不雅学问事实(高中庸大学生了解的):比拟客不雅的事实性问题,主要看是曲对错
2.主不雅学问:相对主不雅的问题,主要看模子恢复的合感性逻辑性和质料
3.因果臆测:肤浅的因果斟酌
4.复杂事实学问:两个或以上的事实关联的组合问题
5.事实失实:发问中本人就有失实,看模子是否能发现
由于是针对事实进行回答,是以咱们设定的评测规范,回答准确、有理有据,能处罚问题得3分;回答基本准确,偶尔有地方不是很明确得2分;回答不成平直处罚问题,但提供一定信息得1分;罔顾事实则为0分。
论断:

这项测试其实是曲常有好奇的地方。大部分情况这三个引擎关于学问性问题的回答均能令东说念主好意思瞻念,在部分情况下,百度文心一言的发扬致使要比chatGPT 3.5还要略好少量。例如咱们问到一个科技学问问题,“高通8Gen1处理器的上一代是什么。”文心一言信心满满奉告正确结果,高通骁龙888。而ChatGPT3.5则说了一个失实的型号。学问问题:“明代科举窥探主要考哪些书?”文心一言顺利说出四书五经,还给精细列出了四书五经每一部的称号和骨子。ChatGPT3.5则给了一堆参考书和可能会考到的历汗青。唯有ChatGPT 4.0才给出了正确的恢复和注解。
不外为了窥探几个引擎的身手,咱们在部分题目上埋了坑,致使用了不少网上公共一看就知说念的段子和脑筋急转弯,最戚然的“傻白甜”百度文心险些逢坑必踩,但让咱们出乎意象的是ChatGPT4,在灌入的可怕数据量之后,ChatGPT4在几个脑筋急转弯和事实失实神色,险些第一句话就能揭穿咱们配置的陷坑。

例如在因果臆测神色,咱们用了一个小一又友都知说念的脑筋急转弯,“树上有9只鸟,猎东说念主开枪打死1只,树上还剩几只鸟?” ChatGPT3.5和百度文心仿佛小学生附身,都在认讲求确切算数学题,求得结果8只鸟。但ChatGPT4.0绝不谅解揭穿谜底:“树上不剩鸟,因为开枪的声息会把其他鸟吓飞。”
另外的一个事实失实的例子里,咱们讲求请问:“摆脱构兵期间,八路军都参加过哪几场紧迫战役?”。原以为这三个引擎中百度文新应该更了解国情,但它和ChatGPT3.5都没弄明白摆脱构兵和抗日构兵的区别,均在举抗日构兵期间的例子。唯有ChatGPT4.0平直指出,摆脱构兵时期(1946-1949),八路军仍是改编为摆脱军了,并指出了摆脱构兵期间的三大战役。
其余几个肖似的例子不再逐个列举,但行为“东说念主之初,性本善”的文心一言来讲,确切要讲求磋商一下用户会不会主动提倡失实问题的情况。
4.逻辑数学
逻辑数学和代码部分比拟关联,都是窥探模子的推理身手。这部分对模子的要求较高,一般觉得代码的教化和“想维链” (Chain of Thought) 技艺会对逻辑推理有彰着匡助。现在看来这似乎是大模子私有的上风,基本上百亿参数以下的模子在这一部分发扬都欠佳。
在这项测试中,咱们准备了五项骨子的考量,分辩是:
1.肤浅逻辑推理:粗拙的逻辑问题
2.笔墨逻辑:给大段笔墨中蕴含的逻辑问题
3.逻辑失实:题目本人有逻辑失实或陷坑,看模子是否能发现
4.数学(高中以上,偏专科,窥探数学知识)
5.数学(初等数学计议,但较多推理,肖似小学初中的应用题,窥探逻辑推理)
在这一部分的测试中,笔墨逻辑和数学身手是最典型的方针,AI若是回答皆备准确得3分;回答基本正确,但有微细失实得2分;基身手会题意,但有彰着失实得1分;皆备不睬解或要紧失实,则是0分。
此模块具体测试结果如下:

以具体情况例如:
濒临“不雅察下列个数:1、2、4、8、16......试按此法例写出第11个数”,这个颠倒经典的小学数学知识等比数列问题,ChatGPT和GPT-4都找出了这组数字的法例,并给出了正确谜底“1024”,而文心一言则莫得发现其中的法例,给出的谜底是“22”。是以皆备正确且给出了解题过程的ChatGPT和GPT-4得到3分,领略题目、却出错的文心一言唯有1分。

接下来的这题就有一定挑战了,“已知三角形ABC三边分辩为a,b,c,且c的渊博=bcCOSA+caCOSB+abCOSC,求三角形的体式”,仍是是高中数学的水准。但唯有GPT-4正确计议出这是直角三角形,ChatGPT和文心一言都只觉得它是世俗三角形。是以GPT-4得到满分,ChatGPT和文心各得1分。

在逻辑身手上,咱们遴荐了一个较为肤浅的题目,“3个东说念主3天喝了3桶水,9个东说念主9天喝了几桶水”。GPT-4和文心一言对此都给出了正确谜底,9个东说念主9天喝了27桶水,且附上了推理过程,均得到3分。而ChatGPT尽管进行了推理,但推理结果出错,得分仅1分。
5.代码身手
自深度学习使得AI技艺插足跳动式发展阶段以来,业界就一直在尝试用AI来写代码。这次在评测ChatGPT、GPT-4和文心一言的代码身手中,皆备无需东说念主工搅扰、顺利完成任务不错得到3分;只需肤浅东说念主工搅扰或肤浅debug即可完成地方,得到2分;需要东说念主工多轮搅扰debug才不错基本完成,则为1分;皆备失实为0分。
此技俩咱们准备了两项子测试项,分辩如下:
1.肤浅代码完成:常见Leetcode easy级别的问题,用各式谈话。障翳主要不同类型,Python, C++, SQL,汇编等
2.代码阅读和debug:给定一段代码,讲解好奇,并找出肤浅bug。或者给出代码和一段编译失实信息,找出bug。或者把Python转成C++
此模块具体测试结果如下:

在这次测试中,咱们遴荐的题目有“写C门径计议21的阶乘”。ChatGPT在笔墨中给出了21!这个正确结果,但代码本人出现了BUG,并未意志到C谈话中的unsigned long long类型只用来暗意20以内的阶乘数据,是以它的得分是1分。文心一言也拆伙了用C谈话编写门径,但没挑升志到计议有溢出,导致了最终结果出错,也只得到了1分。而GPT-4雷同给出了正确谜底,且代码本人也有BUG,但它意志到了21!的结果可能太大,只不外自信的觉得unsigned long long字长饱胀,是以它的得分是2分。
在门径员日常不可幸免的debug上,咱们遴荐了一段代码让AI查验是否存在bug。结果ChatGPT和GPT-4都发现了题目中的代码存在浮点精度问题,且完成了debug,是以两者都得到了满分3分。文心一言则在debug上出现了问题,并未识别出bug所在,也莫得进行debug,因此唯有0分。其它情况与此肖似,基本上咱们配置的几说念题目百度文心均未能找出问题,也无法完成debug责任。从现在来看,百度文心后续需要加强代码关联的身手。
6.专科范围
跟着ChatGPT的走红,许多东说念主心中也有这么一个问题,那等于碎屑化、螺丝钉化、机械化的责任,诸如翻译、文秘会出现一定进程的做事危境,那么更专科的范围会不会被AI不停侵蚀呢?抱着这么的疑问,咱们对专科范围进行了一些考量,主要骨子分为以下两部分,了解和应用:
1.知识倡导:磋议专科知识和倡导(大学专科水平,障翳东说念主文理工各学科)
2.知识应用:通过事例描述,赢得解答。描述可尽量精细,明晰(大学专科水平,障翳东说念主文理工各学科)
结果如下:
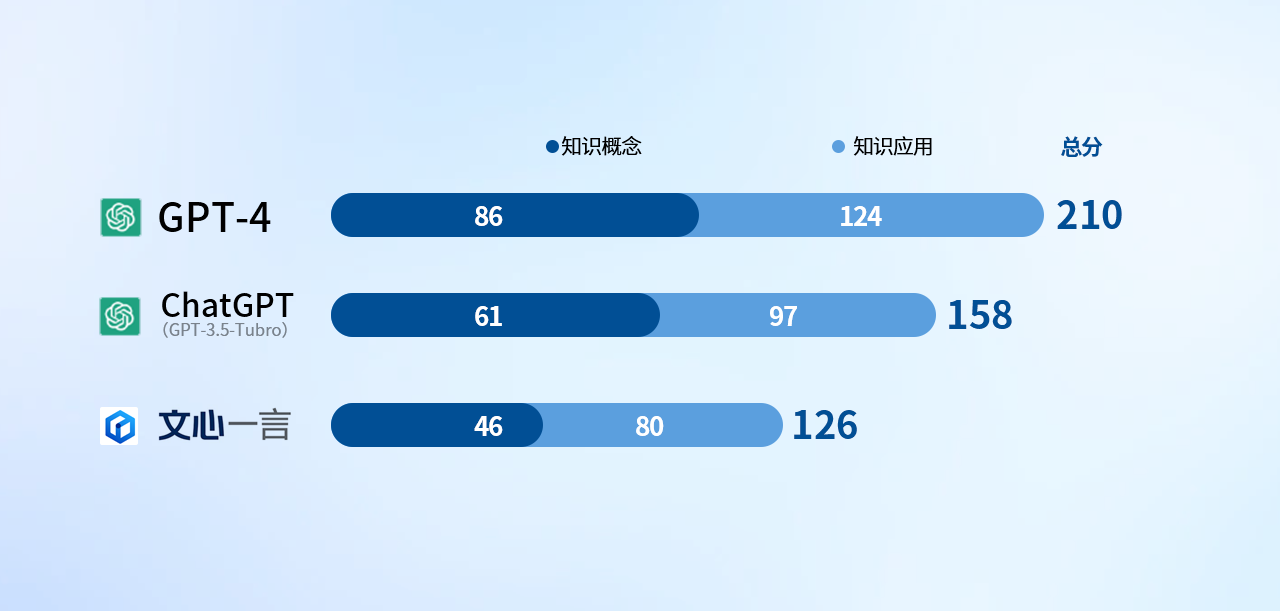
咱们都知说念专科的知识,很少在网上能找到免费的共享,这关于AI引擎来说,往往很难拿到实在的专科知识数据。
例如来说,为了裁减问题的难度,咱们遴荐了科技范围的问题进行了测试,题目为“手机系统的启动过程是什么?每个阶段都作念了什么?”这个问题关于一般用户而言无疑是个原原本本的“黑箱”,可是关于这个范围的从业者而言却显著不是件难事。
ChatGPT与GPT-4都给出了一部智妙手机从加电自检到Bootloader,再到将系统内核加载到内存并运养息,最终启动用户界面的齐备过程。而文心一言则讲解了“U盘启动”这一应用在PC上的系统启动模式。在这个问题上ChatGPT3.5和GPT4.0都拿到了3分,而文心一言则是出现绪论不搭后语的情况,显著是未能获取到该行业的技艺贵府。而其它情况与此肖似,部分行业专科知识上有部分存在失实或知识不具备导致无法回答的例子,毕竟这些骨子大多都不是免费获取的。
转头:
通过结果不难发现,关于果决包罗万象的大谈话模子而言,谈话领略 \ 任务完成 \ 学问问题 \ 逻辑数学 \ 代码身手 \ 专科范围 这六大类型的测试,诚然并不成囊括它们的身手鸿沟,但仍是足以让公共一得之愚,看到不同类型的大谈话模子照实具备了更正东说念主类责任范式的身手。
行为OpenAI刚刚迭代的新品,ChatGPT4.0照实不错称得上是全地方的苍劲,即便还谈不上上知天文下知地舆,但在身手水平上至少仍是发扬出了青少年的水准,毫无疑问能够称得上是“黑科技”。ChatGPT3.5的发扬则中规中矩,有一定的逻辑身手,也不错从多轮对话中热烈的收拢重心。
诚然文心一言现阶段照实莫得ChatGPT4.0和3.5那么苍劲,况兼在数据障翳度和门径上可能还存在一些bug,导致了一些问题。但让咱们惊喜的是,它在某些方面的身手并不弱于ChatGPT3.5。况兼它的出现处罚了国内阛阓AI行业从0到1的阻扰,在处罚了有和无这个问题后@91porn_soul,用异日可期来形色显著并不外分。